Simple political actor classification with "soft" dictionaries
As political scientists, we are often interested in using text to understand the actions of political actors. Thankfully, have a growing set of tools for identifying political actors in text, including named entity recognition and dependency parses, custom event models, or hand labeling events text. But once we’ve extracted political actors from text, we usually want to categorize them in some way. For instance, we might want to know whether a particular actor is a government agency, rebel group, or NGO.
This recently came up in a project on a new end-to-end political event coder. Once we extract actors from text (in our case, using a custom question-answering model), how we assign a category to the actors?
The old way to do this was to use a dictionary of known actors and their category labels and compare the extracted actors to the dictionary. If the extracted actor has a match in the dictionary, we can assign it the corresponding category. But exact matching is a brittle technique that relies on on dictionaries of every alternative name for every possible actor:

This approach relies on enormous effort to construct dictionaries and leads to many false negatives (see, for example, the poor coverage of the CAMEO dictionaries for identifying events).
A more modern way to categorize actors is to extract a large number of actors from text, hand-label them with their correct roles, and train a classifier to assign labels to new actors. This approach is more robust than dictionaries, but it it still requires a lot of hand-labeling, which is time-consuming and expensive.
An alternative approach, which works remarkably well, is to combine a very short dictionary of terms with a transformer-based classifier. This “soft” dictionary approach avoids the need to hand-label a large number of actors to train a classifier or develop a comprehensive dictionary of terms. It consists of two steps: defining a short list of terms for each category of actors, and training a transformer-based classifier to assign labels to new actors.
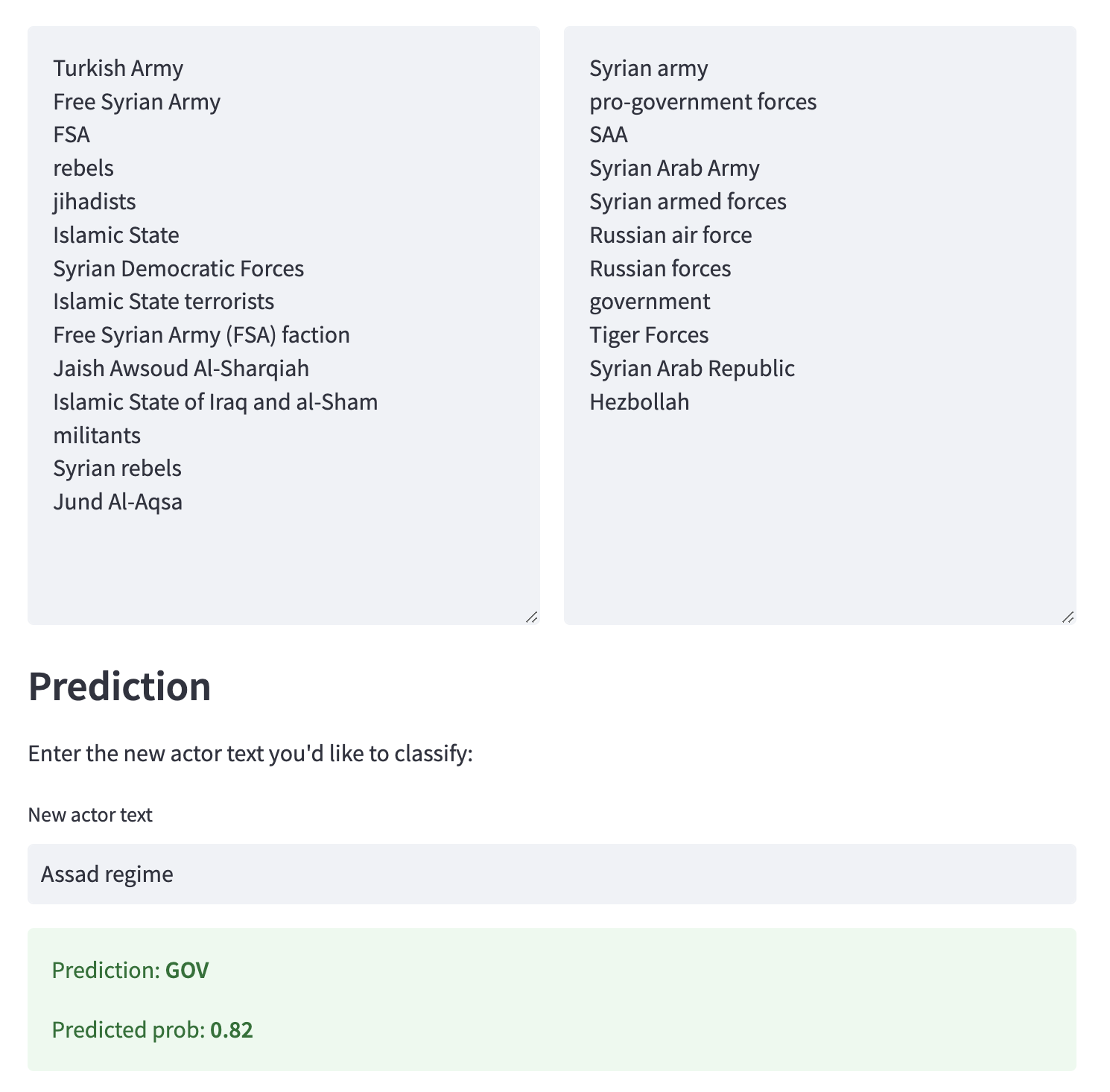
First, for each category of actors we’d like to classify, we hand-define a short list of actors for each. For instance, if we were studying the civil war in Syria and wanted to distinguish between government/pro-government forces and rebel/anti-government forces, we can quickly come up with a short list of actors based on our knowledge of the conflict. For example, we might define the following terms for government or government-aligned forces:
Syrian army
government forces
SAA
Syrian Arab Army
Syrian armed forces
Russian air force
Russian forces
government
Tiger Forces
Syrian Arab Republic
Hezbollah
And the following terms for rebel, rebel-aligned, or anti-government actors:
Free Syrian Army
FSA
rebels
jihadists
Turkish Army
ISIS
Islamic State
Syrian Democratic Forces
Islamic State (ISIS)
Islamic State terrorists
Free Syrian Army (FSA) faction
Jaish Awsoud Al-Sharqiah
Islamic State of Iraq and al-Sham
militants
Syrian rebels
Jund Al-Aqsa
We then can train a classifier on these small sets of actors. The power of this classifier comes from its use of a sentence transformer model, which allows us to train a model with very few training examples. The sentence transformer model is a language model that’s pretrained on a large amount of text. It represents each of the input passages of text as a fixed-width embedding that optimized for downstream tasks like classification. Sentence transformers integrate well with huggingface, so we can just load the pretrained model from the hub:
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
import numpy as np
def load_trf_model(model_dir='sentence-transformers/paraphrase-MiniLM-L6-v2'):
model = SentenceTransformer(model_dir)
return model
trf = load_trf_model()
We then encode both of our patterns using the sentence-transformer model, label them by the their class, and combine them into a data frame. Then we train the simplest possible classifier, a logistic regression, on the embeddings.
def train_model(trf):
with open("patterns_rebel.txt", "r") as f:
rebel_patt = f.read()
rebel_patt = rebel_patt.split("\n")
with open("patterns_gov.txt", "r") as f:
gov_patt = f.read()
gov_patt = gov_patt.split("\n")
trf_rebel = trf.encode(rebel_patt, device='cpu')
trf_gov = trf.encode(gov_patt, device='cpu')
X = np.vstack([trf_rebel, trf_gov])
y = np.concatenate([np.ones(len(trf_rebel)), np.zeros(len(trf_gov))])
clf = LogisticRegression(random_state=0).fit(X, y)
return clf
clf = train_model(trf)
To generate predictions for a new actor, we just encode the new actor text, apply the pretrained classifier, and return the label.
def predict(new_text, trf=trf, clf=clf):
embedding = trf.encode(new_text)
label = clf.predict(embedding.reshape(1, -1))
if label[0] == 1:
return "REBEL"
else:
return "GOV"
predict("Assad regime")
The encoder and logistic regression are fast enough that we can retrain them on the fly.
Live demo
Click here for an interactive demo:
If this is helpful, you can read the rest of the “bag of tricks” paper on efficient event data production:
@article{halterman_et_al2023creating,
title={Creating Custom Event Data Without Dictionaries: A Bag-of-Tricks},
author={Andrew Halterman and Philip A. Schrodt and Andreas Beger and Benjamin E. Bagozzi and Grace I. Scarborough},
journal={arXiv preprint arXiv:2304.01331},
year={2023}
}
And to get future blog posts in newsletter form, you can sign up here:
Andy Halterman
Assistant Professor, MSU Political Science
My research interests include natural language processing, text as data, and subnational armed conflict