Introducing Mordecai 3: A Neural Geoparser and Event Geocoder in Python

Researchers working with text data are often faced with the problem of identifying place names in text and linking them to their geographic coordinates. In social science, we might want to measure news coverage of specific locations, track discussions of specific places in government documents, or geolocate events such protests to the locations where they occur. To do any of these tasks, we need to geoparse text–identify place names in text and resolve them to their entries in a geographic gazetteer. Mordecai3 is a new end-to-end geoparsing library that can can identify places in text and resolve them to their geographic coordinates. It’s available as a Python library with an accompanying technical report.
To get future blog posts in newsletter form, you can sign up here:
What is geoparsing?
Geoparsing text consists of two steps:
- Identifying place names in text (toponym recognition, or named entity recognition for place names). This is the task of identifying place names in text, such as “Paris” or “Aleppo”.
- Resolving place names to their geographic coordinates or entry in a gazetteer of place names (toponym resolution). This main difficulty in this step is handling ambiguous place names: “Aleppo” could refer to the city in Syria, the governorate in Syria, or the township in Pennsylvania.
To do the first step, Mordecai uses spaCy’s transformer-based NER model for identifying place names. The transformer-based model is slower than the standard spaCy model, but it’s more accurate and gives us access to the contextual embeddings we need to do the second step.
The second step is where the core innovation of Mordecai 3 is. Mordecai 3 begins by querying the Geonames gazetteer in a custom local Elasticsearch index to find candidate locations for each place name. Then, it uses a neural ranking model to select the best match from the candidate locations, drawing on features from the place name, other places in the text, the contextual content of the document, and features from the Elasticsearch query. This model is trained on a diverse set of existing training data, along with several thousand newly annotated examples, to select the best match from the candidate locations. The result is a highly accurate geoparser that performs well on both new and existing geoparsing datasets, with an accuracy of 94. Further details are available in Mordecai’s technical report.
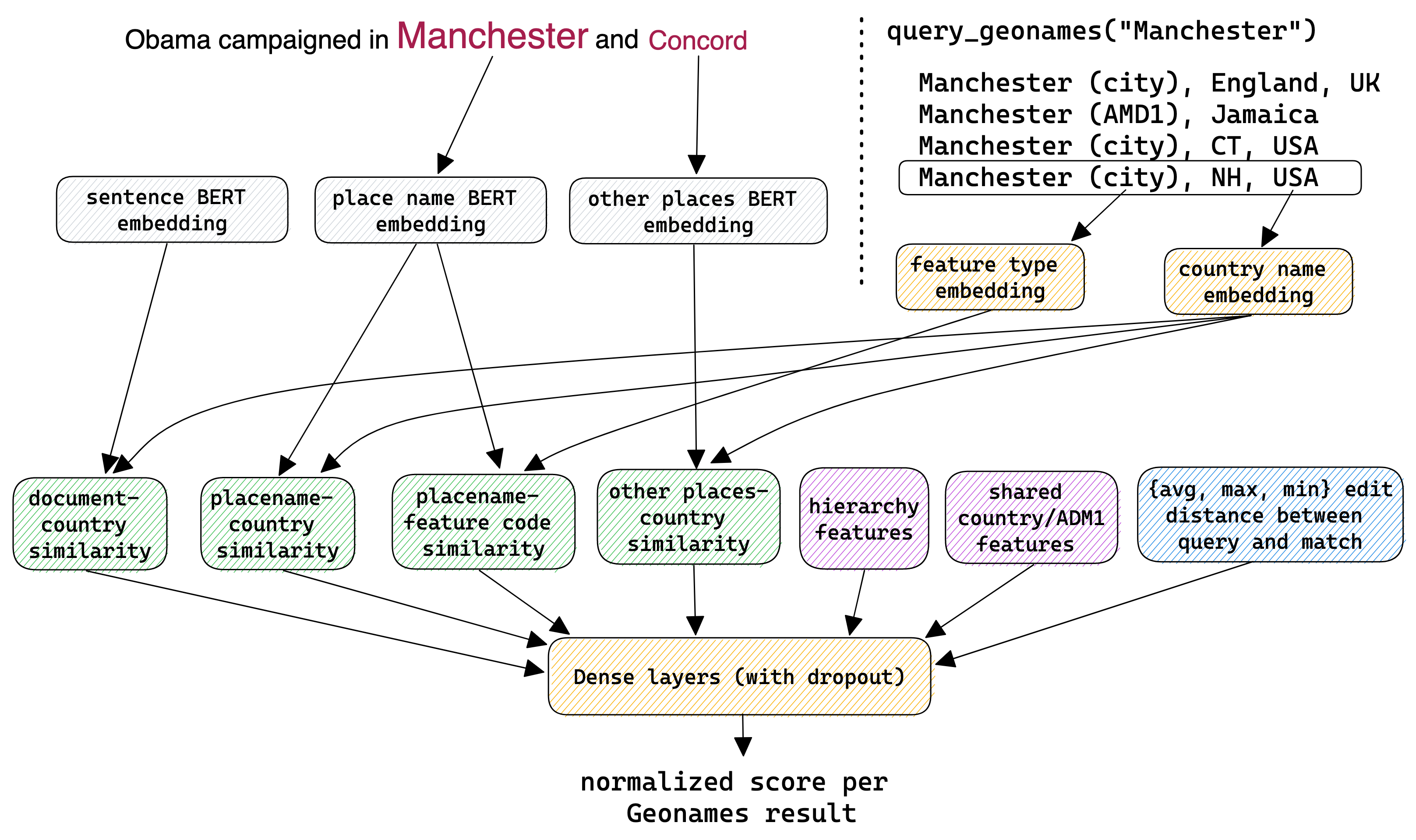
Finally, Mordecai 3 can also perform event geoparsing, the process of identifying for a given event reported in text, the location where it was reported to occur. To do so, it uses an off-the-shelf question-answering model to identify the place name where the event was reported to have occurred. It then finds the geolocated entity that overlaps with the place name. This is a simple but fairly effective technique. Using event-specific questions can greatly improve the accuracy of event geoparsing, and this is an area of ongoing research.
Installing Mordecai 3
Mordecai 3 is available as a Python library on
PyPI. You can install it with pip:
pip install mordecai3
To use it, you’ll also need an offline copy of the Geonames gazetteer. You can follow the instructions on the es-geonames repository to download and index the gazetteer in Elasticsearch. Depending on your system, this may take 20-60 minutes.
Mordecai 3 will automatically install the necessary packages, but you’ll also need to download the spaCy transformer model for identifying placenames and for preprocessing the text for the neural similarity model. You can do this with the following command:
python -m spacy download en_core_web_trf
How can I geoparse documents to identify placenames and link them to their geographic coordinates?
One you have Mordecai 3 installed and the Geonames gazetteer indexed in Elasticsearch, you can use it to geoparse documents. The following code snippet shows how to use Mordecai 3 to geoparse a document and extract the place names and their geographic coordinates.
from mordecai3 import Geoparser
geo = Geoparser()
geo.geoparse_doc("I visited Alexanderplatz in Berlin.")
As output, you’ll get the following:
{'doc_text': 'I visited Alexanderplatz in Berlin.',
'event_location_raw': '',
'geolocated_ents': [{'admin1_code': '16',
'admin1_name': 'Berlin',
'admin2_code': '00',
'admin2_name': '',
'city_id': '',
'city_name': '',
'country_code3': 'DEU',
'end_char': 24,
'feature_class': 'S',
'feature_code': 'SQR',
'geonameid': '6944049',
'lat': 52.5225,
'lon': 13.415,
'name': 'Alexanderplatz',
'score': 1.0,
'search_name': 'Alexanderplatz',
'start_char': 10},
{'admin1_code': '16',
'admin1_name': 'Berlin',
'admin2_code': '00',
'admin2_name': '',
'city_id': '2950159',
'city_name': 'Berlin',
'country_code3': 'DEU',
'end_char': 34,
'feature_class': 'P',
'feature_code': 'PPLC',
'geonameid': '2950159',
'lat': 52.52437,
'lon': 13.41053,
'name': 'Berlin',
'score': 1.0,
'search_name': 'Berlin',
'start_char': 28}]}
The output has three keys: the text of the original document, the location identified as the event location (blank in this case), and a list of geolocated entities. Each geolocated entity has a number of fields, including the search place name, the name of the matched Geonames entry, its geographic coordinates, its administrative hierarchy, and the entity’s location within the original document. The score field indicates the confidence of the geoparser in the match.
Differences between Mordecai2 and Mordecai3
Mordecai 3 is a complete rewrite of the original Mordecai geoparser. It uses a new neural similarity model to perform toponym resolution, and it uses a new question-answering model to perform event geocoding. for their own use cases. Mordecai 2 was trained with very limited data and relied heavily on static word embeddings. Mordecai 3 is much better at using the context of the document, and also has an improved ranking model that uses more features from the query and candidate location.
To get future blog posts in newsletter form, you can sign up here:
Andy Halterman
Assistant Professor, MSU Political Science
My research interests include natural language processing, text as data, and subnational armed conflict