The Good Judgement Project and Bayes' Calculator
It’s been a very forecast-y week. Between (finally) reading Phil Tetlock’s excellent
Expert Political Judgement, going to a half dozen panels at ISA on forecasting and event data, and today’s
NPR story about the
Good Judgement Project, I’ve been thinking a lot about how to make political forecasts and how we know when they’re good. I wanted to share one of the tools I’ve been using for forecasting and calculating subjective probabilities. The
Good Judgement Project is a study of political forecasting, run by Phil Tetlock and others and funded through
IARPA’s ACE program (the NPR story linked to above gives a good background). The project aggregates forecasts by participants, studying whether some people can consistently out-perform chance and whether those people can be identified and trained. Since becoming a participant this summer, I’ve thought a lot about subjective probability and how to update my beliefs in light of new evidence. Bayes’ rule is perfect for this task, and I’ve tried to use it to anchor my forecasts to the base rate or to my prior belief about the event occurring. Because the Good Judgement Project (in my experimental condition, at least) simply asks for a point estimate for the probability of event occurring, the basic version of Bayes’ Rule with point estimates works well for this. [caption id="attachment_106” align="alignnone” width="605”]
 A screenshot of what the forecasting platform looks like for the Good Judgement Project[/caption] If you can establish p(H), p(Evidence|Hypothesis), and p(Evidence|~Hypothesis), you can calculate your posterior trivially, either by hand or in an simple program. While this approach works for simple anchoring to the base rate/prior, it omits one of the great strengths of Bayesian analysis, which is the information about uncertainly that’s contained in the distributions, rather than point estimates, for the prior and posterior. Real, full Bayesian analysis (see, e.g. on Gelman et al.‘s excellent
Bayesian Data Analysis) treats all inputs and outputs as probability distributions, and calculates the likelihood based on the probability of observing a series of data points, given a parameter. The posterior is then approximated computationally. This full analysis seems excessive and doesn’t necessarily make sense for inputs that are completely subjectively determined. What I wanted, instead, was a way of melding a completely subjective prior distribution with a simple subjective estimate of the likelihood (i.e., how likely is this event assuming the hypothesis is true, and how likely is the event assuming the event won’t take place). [caption id="attachment_96” align="alignnone” width="605”]
A screenshot of what the forecasting platform looks like for the Good Judgement Project[/caption] If you can establish p(H), p(Evidence|Hypothesis), and p(Evidence|~Hypothesis), you can calculate your posterior trivially, either by hand or in an simple program. While this approach works for simple anchoring to the base rate/prior, it omits one of the great strengths of Bayesian analysis, which is the information about uncertainly that’s contained in the distributions, rather than point estimates, for the prior and posterior. Real, full Bayesian analysis (see, e.g. on Gelman et al.‘s excellent
Bayesian Data Analysis) treats all inputs and outputs as probability distributions, and calculates the likelihood based on the probability of observing a series of data points, given a parameter. The posterior is then approximated computationally. This full analysis seems excessive and doesn’t necessarily make sense for inputs that are completely subjectively determined. What I wanted, instead, was a way of melding a completely subjective prior distribution with a simple subjective estimate of the likelihood (i.e., how likely is this event assuming the hypothesis is true, and how likely is the event assuming the event won’t take place). [caption id="attachment_96” align="alignnone” width="605”]
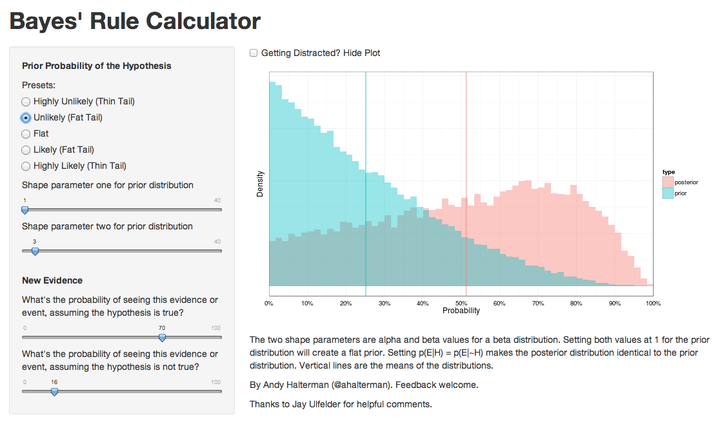
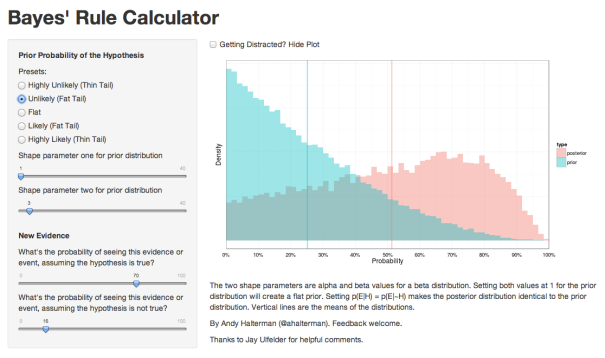 BayesCalculator on RStudio’s Shinyapps site.[/caption] This
calculator is a simple way of eliciting a prior distribution, asking about the likelihood of an event under the prior distribution, and then spitting out an update probability distribution based on that information. I wrote it in R using ggplot2 and Shiny (with plans to update it for ggvis now that it’s out). It’s hosted by shinyapps.io on an Amazon EC2 Micro instance, so give it some time to update after you change your parameters. Any feedback on the calculator is welcomed and I hope you find it useful.
BayesCalculator on RStudio’s Shinyapps site.[/caption] This
calculator is a simple way of eliciting a prior distribution, asking about the likelihood of an event under the prior distribution, and then spitting out an update probability distribution based on that information. I wrote it in R using ggplot2 and Shiny (with plans to update it for ggvis now that it’s out). It’s hosted by shinyapps.io on an Amazon EC2 Micro instance, so give it some time to update after you change your parameters. Any feedback on the calculator is welcomed and I hope you find it useful.
Andy Halterman
Assistant Professor, MSU Political Science
My research interests include natural language processing, text as data, and subnational armed conflict